
«تکسونومی در برابر آنتولوژی»؛
اینکه «چه تفاوتی بین تکسونومی و آنتولوژی وجود دارد؟» از سؤالاتی است که معمولاً در حوزه بررسی سیستمها، علم داده و کامپیوتر پیش میآید. برای جواب دادن به این سؤال پاسخهای ساده و کوتاهی وجود دارد (مثل این که تکسونومیها نظامهای سلسلهمراتبی (hierarchies) و آنتولوژیها شبکههای معنایی (semantic)) هستند؛ بااینحال ممکن است تمایز قائلشدن بین تکسونومی و آنتولوژی برای برخی دشوار باشد. دلیل این دشواری هم قطعا به دلیل همپوشانی زیادی است که بین این دو مفهوم وجود دارد. آنتولوژیها میتوانند دارای تکسونومیها باشند و از طرف دیگر تکسونومیها میتوانند از منظر معنایی (سمانتیک) غنی شوند تا مشابه آنتولوژیها شوند. برنامههایی که در این حوزه استفاده میشوند هم (مثل PoolParty) توانایی ساخت هر دو را دارند.
ریشۀ این دو مفهوم کجاست؟
یکی دیگر از تفاوتهای مهم بین تکسونومی و آنتولوژی به ریشه این دو مفهوم باز میگردد. تکسونومی اطلاعات (نه تکسونومی بیولوژیکی) از رشته علم کتابداری سرچشمه گرفته است. به طور خاص، از نظر نگارنده تکسونومیها با ترکیب انعطافپذیری از سیستمهای طبقهبندی شده (classification systems) و اصطلاحنامهها (thesauri)، تکاملیافتند و بهوجود آمدهاند. از طرفی، آنتولوژیها (خارج از معنای آنها در فلسفه) معمولاً بهعنوان بخشی از علوم کامپیوتر تدریس و تحقیق میشوند. توجه کنید همانطور که پیشتر به همگرایی این دو مفهوم اشاره کردم، این همگرایی در علم کتابداری و علوم کامپیوتر در حوزه علم اطلاعات هم وجود دارد ولی باز هم علم کتابداری/اطلاعات و علم کامپیوتر/اطلاعات، رویکردهای متفاوتی نسبت به مسائل دارند و یکی نیستند.
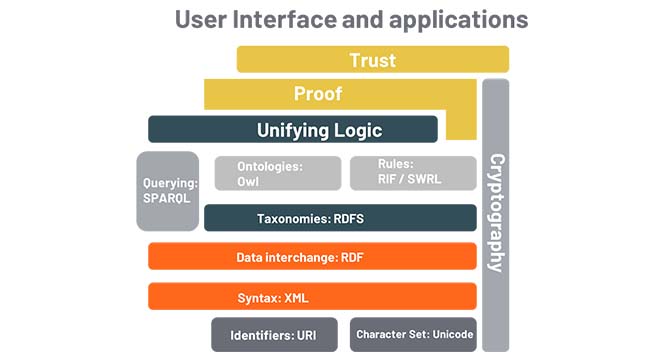
علاوه بر اینها، تکسونومیها به یکی از موارد پراستفاده و مهم در معماری اطلاعات، طراحی تجربه کاربر، مدیریت محتوا و مدیریت داراییهای دیجیتال تبدیل شدهاند. آنها همچنین با مدیریت اصطلاحات، جستجو و بازیابی اطلاعات ارتباط دارند. از سوی دیگر، آنتولوژیها به حوزهای پرطرفدار در علم داده، مهندسی داده و مدیریت دادههای گرافی تبدیل شدهاند. آنها مفاهیمی مثل نظریۀ مجموعهها را از ریاضیات و منطق را از فلسفه وام گرفتهاند.
همگرایی آنتولوژیها و تکسونومیها!
یکی از رویههای معمول در مدیریتِ داده، اطلاعات و دانش، همگرایی سیستمها، روشها و تکنولوژیها است. آنتولوژیها و تکسونومیها هم از این قاعده مستثنی نیستند. برای همگرایی این دو تلاشهای زیادی صورتگرفته است. همگرایی بین این دو تا جایی پیش رفته که معمولاً تکسونومی و آنتولوژی بهجای یکدیگر به کار برده میشوند. تاحدیکه انگار این دو اساساً یک مفهوماند. با وجود تمام این تفاسیر، تکسونومی و آنتولوژی مفاهیم جدایی هستند و نباید یکی دانسته شوند. هرچند که این دو مفهوم هر روز بیشتر و بیشتر در حال ترکیبشدن با یکدیگرند.
کاربردهای اصلی این دو مفهوم:
تکسونومی
با این که هم تکسونومیها هم آنتولوژیها سیستمهای سازماندهی دانش هستند، هر دو امکان دسترسی به اطلاعات موردنظر را فراهم میکنند ولی کاربردهای بهخصوص هر یک متفاوت از دیگری است. کاربرد اصلی تسکونومیهای اطلاعات، استفاده در برچسبزنی منظم، مداوم و همچنین بازیابی جامع اقلام محتوا است. این محتوا میتواند متن، اجزای تشکیلدهنده (بخشهای) متن، صفحات وب، اینترنت و یا داراییهای دیجیتالی (تصویر، ویدئو، صدا و …) باشد.

بهعبارتدیگر کاربرد اصلی تسکونومیها برای این است که یک محتوا درباره چیست؟ (هرچند بررسی اینکه محتوا/متن از چه نوعی است هم بخشی از کاربرد تکسونومیها به شمار میآید). برای روشنتر شدن موضوع اینطور در نظر بگیرید که تکسونومیها برای سوالاتی مثل «تمام منابع اطلاعاتی درباره فلان چیز را گردآوری کن» یا «لیستی از محصولاتی با فلان ویژگی را گردآوری کن» پاسخ قابل قبولی به شما میدهند؛ البته مشخصکردن خصوصیات و محدوده قیمت با فیلترها هم کار دیگری است که میتوانند در ادامه انجام دهند.
آنتولوژی
آنتولوژیها اما بهخاطر در برگرفتن جزییات یا لینکدهی به فَردیتها (individuals) {برای جلوگیری از ایجاد سوءتفاهم با انسانها از کلمه «افراد» استفاده نشده است}/نمونهها و همچنین داشتن ویژگیهای فراوان، بیشتر بر روی مشخصات و ویژگیهای خاص دادهها تمرکز میکنند. پس نتیجه میگیریم که ویژگیهایی مثل بازیابی دادهها، مقایسه دادهها و تجزیهوتحلیل آنهابا آنتولوژی امکان پذیر است.
همچنین میتوان گفت: آنتولوژیها میتوانند به درخواستهای پیچیدهتر و چندمرحلهای پاسخ دهند. مثلاً میتواند «لیستی از محصولات که دارای فلان ویژگی هستند را گردآوری کند». آنتولوژی اینکار را طوری پشتیبانی میکند که مثلا بتوانید مشخصاتی مثل محدوده قیمت این محصولات در فروشگاههای ایرانی که حداقل درآمدشان 50 میلیون تومان است را محدود کنید.
ویژگیهای بارز این دو مفهوم:
تکسونومی و آنتولوژی هر دو یک هدف را دنبال میکنند: توصیف یک حوزه دانش بهعنوان مجموعهای از موجودیتها که در گروهها یا دستههای مختلفی دستهبندی شدهاند. گروهها و دستههایی که بینشان میتوان روابطی تعریف کرد. آنتولوژیها هنگام توصیف، روابط و جزئیات بیشتری را شامل میشوند. ویژگیها و خواص هم در آنتولوژیها بهصورت گستردهتری وجود دارند. بااینحال از هر دو مفهوم، برای یادداشتبرداری و مشخصکردن تعاریف استفاده میشود.
بازیابی محتوا در آنتولوژی و تکسونومی چگونه است؟
هنگام مقایسه بازیابی محتوا و داده، تکسونومیها میتوانند یک فایل صفحه گسترده (مانند Excel، google sheet و …) را بازیابی کنند، آنتولوژیها اما میتوانند دادهها را از سلولهای جداگانه در صفحات گسترده بازیابی کنند. بهعبارتدیگر آنتولوژیها توانایی این را دارند که دادهها را در یک پایگاهداده بهصورت مستقل و جدا از هم بررسی و بازیابی کنند. از این ویژگی آنتولوژیها میتوان در پایگاههای دادۀ رابطهای هم استفاده کرد. امروزه به طور فزایندهای از آنتولوژیها در پایگاههای دادۀ گرافی/ رابطهای استفاده میشود، چرا که ساختار آنتولوژیها خود بهصورت گراف است.
ترمها یا موجودیتها در این دو مفهوم شامل چه چیزهایی است؟
تکسونومیها از مفاهیم (که گاهی تِرمها نامیده میشوند) تشکیل شدهاند؛ میتوان گفت مفاهیم یکسری «چیز» هستند. مفاهیم میتوانند کلی یا خاص باشند. حتی ممکن است شامل موجودیتهای نامگذاری شده (اسمهای خاص منحصربهفرد) باشند. تکسونومیها بین مفاهیم عمومی و موجودیتهای نامگذاری شده که در آنتولوژی با «مفردها» مطابقت دارند، تفاوتی قائل نمیشوند. از سوی دیگر آنتولوژیها دو نوع موجودیت را در نظر میگیرند و بین آنها تمایز قائل میشوند. این دو عبارتاند از کلاسها و مفردها.
کلاسها میتوانند گسترده یا خاص باشند. اما همانطور که از نامشان پیداست، کلاسها، موجودیتی هستند که حاوی چیزی دیگریاند. این چیز دیگر میتواند زیر کلاس یا مفرد باشد.
در مقابل، گرههای برگی (محدودترین مفاهیم در سلسلهمراتب) در یک تکسونومی میتوانند از نظر معنایی کاملاً گسترده باشند و موارد زیادی را در بر گیرند. مفردها آنطور که توسط یک آنتولوژی تعریف میشود، معمولاً موجودیتهای نامگذاری شده هستند (اسمهای خاص) و باید منحصراً مفرد باشند. ممکن است چنین امری واضح نباشد. بهعنوانمثال یک محصول با نام تجاری یک اسم خاص است، اما از نظر اصولی یک مفرد نیست. چرا که موارد متعددی از آن محصول در هر لحظه در اختیار افراد متفاوتی است. در نظر داشته باشید که تعریف مفردها همگانی نیست و اختلافنظر در این باره وجود دارد.
استانداردهای مورد استفاده در آنتولوژی و تکسونومی چیست؟
مضاف بر موارد بالا، تکسونومیها و آنتولوژیها از استانداردهای متفاوتی پیروی میکنند. با این حال میتوان گفت استانداردهای این دو نیز بهنوعی همگرا شدهاند. تکسونومیها استانداردی برای خود ندارند، اما از استانداردهای ANSI/NISO Z.39.19 و ISO 25964 برای رعایت بهترین راهکارها و فعالیتها استفاده میکنند. آنتولوژیها در عوض بر استانداردهای W3C RDF، RDF-Schema و OWL (زبان آنتولوژی وب) منطبق هستند و بر اساس آنها عمل میکنند.
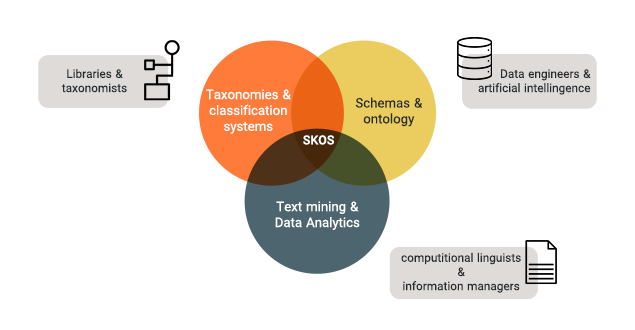
W3C در سال 2009 توصیهنامهای برای تکسونومیها، اصطلاحنامهها و سایر سیستمهای سازماندهی دانش به نام SKOS (سیستم سازماندهی دانش ساده) منتشر کرد و از آن زمان این سیستم به طور گسترده مورد پذیرش قرار گرفت. پایه اصلی SKOS بر اساس RDF است، درست همانطور که پایه استانداردهای آنتولوژی RSF-S است. در نتیجه دستورات SKOS و RDF-S r namespaes را میتوان در یک سیستم سازماندهی دانش ترکیب کرد. یعنی میتوان تکسونومی و آنتولوژی را با هم ترکیب کرد.
چه روابطی بر تکسونومیها و آنتولوژیها حاکم است؟
تکسونومیها از استانداردهای اصطلاحنامه برای روابط پیروی میکنند. روابط سلسلهمراتبی اصطلاحنامه شامل سه نوع است:
- رابطه عمومی خاص یا «این یک … است» (is a)؛
- رابطه عمومی نمونهای (که در آن نمونه یک موجود نامگذاری شده یا اسم خاص است)؛
- رابطه کل _ جزء.
آنتولوژیها فقط روابط عمومی خاص یا «این یک … است» (is a) را دارند که بین کلاسها و زیر کلاسها تعریف میشود. رابطه بین فرد و یک کلاس، در آنتولوژی سلسلهمراتبی در نظر گرفته نمیشود. در عوض این رابطه یک رابطه کلاس _ عضو است. همچنین، رابطه کل جزء در آنتولوژیها سلسلهمراتبی در نظر گرفته نمیشود (اما میتواند بهعنوان یک رابطه معنایی ایجاد شود).
روابط معنایی و روابط عمومی در این مفاهیم به چه شکل است؟
با این که رابطه عمومی، نمونهای از یک نوع رابطه سلسلهمراتبی مجاز در تکسونومی تعریف میشود، موجودیتهای مفهومی نامگذاری شده (اسمهای خاص) اغلب به یک مفهوم کلی مربوطه محدود نیستند. آنها معمولاً در طرح مفهومی جداگانه خود گروهبندی میشوند تا بهعنوان فیلتر جستجو یا جنبه جستجو (search facet ) جداگانه عمل کنند. از دیگر روابطی که ممکن است در تکسونومیها وجود داشته باشد رابطه عمومی «مرتبط» است. هرچند که این رابطه بیشتر در استانداردها یافت میشود.
این یک رابطه دوجهته و متقابل است و معمولاً بین مفاهیمی که در یک طرح مفهومی یکسان قرار دارند استفاده میشود. چنین رابطهای اغلب با یک کلاس در آنتولوژی مطابقت دارد.
آنتولوژیها رابطه عمومی «مرتبط» را ندارند. در عوض روابط معنایی دارند که توسط بهوجودآورنده آنتولوژی تعیین میشوند. درست همانطور که کلاسها از پیش تعریف میشوند. این روابط معنایی در داخل کلاسها استفاده نمیشوند. آنها بین جفتی از کلاسهای خاص مورداستفاده قرار میگیرند. ارائه پیشنهاد در خصوص این که چه چیزی ممکن است مربوط به موارد علاقه کاربر (end-user) باشد در محدوده هدف آنتولوژی که ساختارمندتر و مبتنی بر قوانین است، تعریف نمیشود. آنتولوژیها ممکن است روابط متقابل دوسویه دیگری داشته باشند. روابطی مانند «در کنار … قرار میگیرد (استفاده میشود)»، «همخانواده دارد»، «همراهی میکند» و غیره.
نقش برچسبها در تکسونومی و آنتولوژی:
در تکسونومیها، هر مفهوم یک برچسب ترجیحی در هر زبان برای نمایش دارد. در کنار آن، هر مفهوم میتواند هر تعداد برچسب جایگزین و برچسبهای پنهان در هر زبان برای کمک به تطابق در جستجو یا برچسبگذاری داشته باشد. مدل سنتی استاندارد، اصطلاحات «غیر ترجیحی» را به اصطلاحات «مرجح» هدایت میکرد. در عوض از منظر تکسونومی و محتوا، برچسبهای جایگزین به حد کافی معادل هستند تا برای یک مفهوم معین استفاده شوند؛ بنابراین این برچسبها ممکن است مترادف دقیقی از برچسب اصلی یا برای یکدیگر نباشند. برچسبهای جایگزین شامل مترادفها، مترادفهای نزدیک و احتمالاً حتی اصطلاحات خاصتری هستند که لایق داشتن یک برچسب ترجیحی قلمداد نشدهاند.
در آنتولوژیها عنصر همانی (sameAs) مربوط به OWL برای هم ارزی مفردها در نظر گرفته شده است و کلاس تساوی (equivalentClass) برای هم ارزی کلاسها.
هر دوی آنها هم ارزی دقیقی را نشان میدهند. در آنتولوژیها تقسیمبندی این که یک نام ترجیحی باشد و باقی جایگزین، وجود ندارد. همه نامها ترجیح داده میشوند. استفاده از sameAs و equivalentClass برای استفاده درون یک آنتولوژی واحد نیست، بلکه در بین آنتولوژیهای مختلف استفاده میشود؛ بنابراین این عناصر OWL شبیه رابطه مطابقت کامل exactMatch در SKOS هستند که در طرحهای مفهومی یا تکسونومی استفاده میشود. آنها برخلاف برچسبهای جایگزین از جستجو در درون مجموعهدادههای مشابه پشتیبانی نمیکنند.
قوانین جاری بر تکسونومیها و آنتولوژیها:
SKOS یک مدل داده برای تکسونومیها و اصطلاحنامهها است، اما هیچ قاعدهای برای نحوه استفاده تعیین نمیکند. در عوض، خالق تکسونومی باید سعی کند از دستورالعملهای استانداردهای اصطلاحنامه (ANSI/NISO Z39.19 و ISO 25964-1) پیروی کند و در نظر داشته باشد که چنین دستورالعملهایی واقعاً قانون نیستند.
استانداردهای کیفیت شامل:
- برچسبهای ناهمگون (یعنی برچسب میتواند فقط یکبار برای یک مفهوم، ترجیحی یا جایگزین، و تنها برای یک مفهوم استفاده شود)،
- روابط منفرد (یعنی یک جفت از مفاهیم میتوانند دارای روابط سلسلهمراتبی یا «مرتبط» باشند، اما نه هر دو)، و بدون چرخه سلسلهمراتبی است.
استاندارد آنتولوژیها از سوی دیگر (همان OWL) قوانین بسیاری را در خود دارد. این امر آنتولوژیهای OWL را برای استنتاج و استدلال قدرتمندتر میکند. در مورد شکلگیری یک استاندارد بیشتر بخوانید.
خلاصۀ مقاله در کمتر از 30 ثانیه:
کاربرد اصلی تسکونومیهای اطلاعات، استفاده در برچسبزنی منظم، مداوم و همچنین بازیابی جامع اقلام محتوا است. آنتولوژیها رابطه عمومی «مرتبط» را ندارند. در عوض روابط معنایی دارند که توسط بهوجودآورنده آنتولوژی تعیین میشوند. برخی از ویژگیها بین تکسونومیها و آنتولوژیها مشترکاند. علاوه بر این ترکیب یک تکسونومی با یک آنتولوژی، ترکیبی از کارکردهای تازه را ممکن میسازد. کارکردهایی مثل جستجو، بازیابی محتوا و دادههایی با ارزش در کنار یکدیگر. در نهایت بهخاطر بسپارید بهجای همگرایی تکسونومی و آنتولوژی، آنها بادقت و عمدا ترکیب میشوند تا بتوانند حداکثر مزایا را ممکن سازند.
